학습기법
주성분 분석(PCA)
- 분포된 데이터들의 주성분(Principal Component)을 찾아주는 방법
- 여러 데이터들이 모여 하나의 분포를 이룰 때 이 분포의 주성분을 분석
- 차원 축소: 고차원데이터를 낮은 차원(평면)으로 줄이는 것
- 정보 보존: 이 과정에서 가능한 한 원본 데이터의 분산(정보)을 최대한 보존
- 데이터 요약: 복잡한 데이터셋을 단순화하여 핵심 패턴만 추출
PCA 원리
첫 번째 주성분 (PC1)
- 데이터가 가장 넓게 퍼져 있는 방향 (즉, 분산이 가장 큰 방향)
- 데이터의 구조를 가장 잘 요약하는 축
- PC1만으로도 데이터의 주요 특성을 많이 설명할 수 있음
두 번째 주성분 (PC2)
- PC1과 직교(90도)하면서, 그 다음으로 분산이 큰 영향
- PC1에 담지 못한 나머지 중요한 변화를 담고 있음
PCA를 하는 이유
노이즈 제거
- 고차원 데이터는 종종 노이즈가 많음. PCA를 사용하면 데이터 내의 노이즈 성분을 줄일 수 있음
과적합 방지
- 모댈이 복잡한 데이터를 과적합하지 않도록 차원을 축소하여 일반화 성능을 향상시킬 수 있음
데이터 시각화
- 차원 데이터를 2차원이나 3차원으로 축소해 직관적으로 시각화할 수 있음
장점
- 계산 비용을 감소하는 효과, 전반적인 데이터에 대한 이해도를 높이는 효과
- 변수 간 상관관계 제거: PCA는 변수를 상호 독립적으로 변환하므로 다중공선성 문제를 해결할 수 있음
- 데이터의 중요한 구조 보존: 중요한 정보(분산)를 최대한 보존하면서 차원을 축소해 데이터의 특성을 유지
단점
- 해석의 어려움: 변환 후의 주성분은 기존의 변수들과 직접적인 해석이 어려워짐
- 비선형 구조 파악 불가: PCA는 선형적인 방법이므로 데이터가 비선형 구조일때는 적합하지 않음
- 변수 스케일의 중요성: 변수들의 스케일 차이가 크면 PCA 결과가 왜곡될 수 있음.
- 데이터 손실: 차원 축소 과정에서 일부 정보가 손실될 수 있음
PCA 방법
- Scikit-learn의 차원 축소
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
# StandardScaler로 데이터 normalization 적용
data_scaled = StandardScaler().fit_transform(df_iris.iloc[:, :4])
pca_data = pca.fit_transform(data_scaled)- PCA 적용하기 전에 입력 데이터의 개별 피처들을 스케일링하기
◦ PAC는 여러 피처들의 값을 연산해야 하므로 피처들의 스케일에 영향을 받음
◦ 일반적으로 StandardScaler()로 변환함
◦ 사이킷런의 PCA 객체는 전체 변동성에서 개별 PCA 컴포넌트별로 차지하는 변동성 비율(explained_variance_ratio_) 속성을 제공
군집 분석
- 서로 유사한 정도에 따라 다수의 객체를 군집으로 나누는 작업 또는 이에 기반한 분석
- 유사도가 높은 데이터끼리 그룹화함
- 소속 집단의 정보를 모르고 있는 상태
군집화 활용 분야
고객 세분화
- 마케팅에서 고객을 비슷한 행동·특성 기준으로 그룹화
예) 구매 패턴, 이탈 위험도, 사용 빈도 기반 분류 - 개인화 추천, 타겟 마케팅에 활용
마켓 세분화
- 시장을 동일한 니즈·특성의 집단으로 구분
- 제품 전략, 가격 정책, 지역별 전략 수립에 사용
사용자 행동 분석
- 기반으로 비슷한 행동 패턴을 묶음
예) 뉴스 소비 패턴, 이동 경로, 상품 탐색 방식 등 - UX 개선, 개인화 추천에 활용
비계층적 군집화
- 전체 데이터를 확인하고 특정한 기준으로 데이터를 동시에 구분함
- 각 데이터들은 사전에 정의된 개수의 군집 중 하나에 속하게 됨
종류
- K-Means
- DBSCAN
K-Means
학습 방법
- 사전에 결정된 군집 수 K에 기초하여 전체 데이터를 상대적으로 유사한 K개의 군집으로 구분하는 방법
- 동일 클러스터(군집) 내의 각 데이터들 간의 거리가 가장 짧아지도록 데이터를 주어진 개수의 클러스터로 분류하는 것
특징
- 각 군집은 하나의 중심을 가짐
- 다양한 모양의 군집이 형성될 수 있음
- 같은 중심에 할당된 개체들이 모여 하나의 군집을 형성
- 사전에 군집의 수, K가 정해져야 함.
군집화 방법
1. 데이터 중 임의로 K개의 중심점(Centroid) 설정함
2. 모든 데이터에서 설정된 각 군집의 중심점까지의 거리 계산
3. 모든 데이터를 가장 가까운 중심점이 속한 군집으로 할당
4. 각 군집의 중심점을 재설정함(할당 데이터의 중심으로 중심점 이동)
5. 군집 중심점이 변경되지 않을 때까지 2~5번의 과정을 반복함.
K-Means 실습
Scikit-learn의 K-Means
from sklearn.cluster import KMeans
correct_kmeans = KMeans(n_clusters=3) #cluster 분류 개수 확인
correct_kmeans.fit(data)
correct_kmeans.cluster_centers_ # 데이터와 중심간 거리
correct_kmeans.labels_ # 데이터들의 분류 labels 확인
주요 하이퍼 파라미터
- n_cluster : 군집화 개수(군집의 중심점 개수)
- init : 초기의 군집 중심점 좌표 알고리즘(k-means++)
주요 속성
- labels_ : 각 데이터 포인트가 속한 군집 중심점 레이블임
- cluster_centers_ : 각 군집 중심점
import pandas as pd
import numpy as np
# lib, 데이터 불러오기
data_path = 'datas_ml/Mall_Customers.csv'
df = pd.read_csv(data_path)
df.head()
df.columns
# 독립변수 추출
X = df.loc[:, 'Gender':]
X
sorted(X['Gender'].unique())
from sklearn.preprocessing import LabelEncoder
encoder = LabelEncoder()
X['Genre'] = encoder.fit_transform(X['Genre'])
X데이터 정규화
from sklearn.preprocessing import StandardScaler
features = X.columns
# StandardScaler로 정규화
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X[features])
비지도학습 실습
from sklearn.cluster import KMeans객체 생성
kmeans = KMeans(n_clusters = 3, random_state = 10)비지도학습 실행
y_pred = kmeans.fit_predict(X_scaled)
y_pred
# 예측결과 df에 추가하기
df['Group'] = y_pred
df
# 몇개의 그룹 갯수를 정하면 좋을지 찾는 방법
wcss = []
for i in range(1, 11):
kmeans = KMeans(n_clusters = i, random_state = 10)
kmeans.fit(X_scaled)
wcss.append(kmeans.inertia_)
wcss
import matplotlib.pyplot as plt
plt.plot(wcss)
plt.show()
# 클러스터(그룹)갯수를 정한다.
kmeans = KMeans(n_clusters=2, random_state=10)
y_pred = kmeans.fit_predict(X_scaled)
df['Group'] = y_pred
df
df.loc[df['Group']==1,]
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib import font_manager as fm
import warnings
warnings.filterwarnings('ignore')
# 한글 폰트 설정
plt.rcParams['font.family'] = 'Malgun Gothic'
plt.rcParams['axes.unicode_minus'] = False
# 색상 설정 (5개 그룹)
colors = ['#E63946', '#1D3557', '#F4A261', '#2A9D8F', '#E76F51', '#8338EC']
groups = sorted(df['Group'].unique())
# 1. 소득 vs 지출점수
plt.figure(figsize=(10, 6))
for group in groups:
cluster_data = df[df['Group'] == group]
plt.scatter(cluster_data['Annual Income (k$)'],
cluster_data['Spending Score (1-100)'],
c=colors[group],
label=f'그룹 {group}',
alpha=0.7,
s=60,
edgecolors='white',
linewidth=0.5)
plt.xlabel('연간 소득 (천 달러)', fontsize=12, fontweight='bold')
plt.ylabel('지출 점수 (1-100)', fontsize=12, fontweight='bold')
plt.title('소득 vs 지출 점수', fontsize=14, fontweight='bold')
plt.legend()
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.savefig('cluster_income_spending.png', dpi=300, bbox_inches='tight')
plt.show()
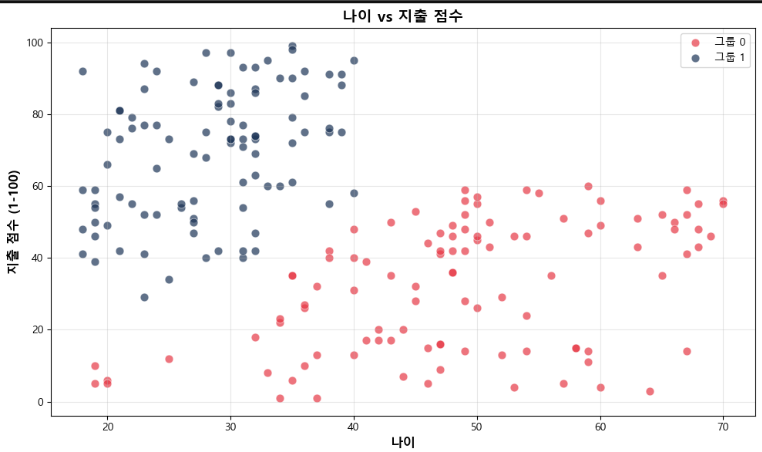
# 2. 나이 vs 지출점수
plt.figure(figsize=(10, 6))
for group in groups:
cluster_data = df[df['Group'] == group]
plt.scatter(cluster_data['Age'],
cluster_data['Spending Score (1-100)'],
c=colors[group],
label=f'그룹 {group}',
alpha=0.7,
s=60,
edgecolors='white',
linewidth=0.5)
plt.xlabel('나이', fontsize=12, fontweight='bold')
plt.ylabel('지출 점수 (1-100)', fontsize=12, fontweight='bold')
plt.title('나이 vs 지출 점수', fontsize=14, fontweight='bold')
plt.legend()
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.savefig('cluster_age_spending.png', dpi=300, bbox_inches='tight')
plt.show()
# 3. 3D 시각화 (소득, 나이, 지출점수)
from mpl_toolkits.mplot3d import Axes3D
fig = plt.figure(figsize=(12, 9))
ax = fig.add_subplot(111, projection='3d')
for group in groups:
cluster_data = df[df['Group'] == group]
ax.scatter(cluster_data['Annual Income (k$)'],
cluster_data['Spending Score (1-100)'],
cluster_data['Age'],
c=colors[group],
label=f'그룹 {group}',
alpha=0.7,
s=60,
edgecolors='white',
linewidth=0.5)
ax.set_xlabel('연간 소득 (천 달러)', fontsize=11, fontweight='bold', labelpad=10)
ax.set_ylabel('지출 점수 (1-100)', fontsize=11, fontweight='bold', labelpad=10)
ax.set_zlabel('나이', fontsize=10, fontweight='bold', labelpad=10)
ax.set_title('3D 클러스터 시각화', fontsize=14, fontweight='bold', pad=20)
ax.legend()
ax.view_init(elev=20, azim=45)
plt.tight_layout()
plt.savefig('cluster_3d.png', dpi=300, bbox_inches='tight')
plt.show()
# 그룹별 통계
print("\n그룹별 통계:")
for group in groups:
group_data = df[df['Group'] == group]
print(f"\n그룹 {group} (n={len(group_data)})")
print(f" 평균 나이: {group_data['Age'].mean():.1f}세")
print(f" 평균 소득: ${group_data['Annual Income (k$)'].mean():.1f}k")
print(f" 평균 지출점수: {group_data['Spending Score (1-100)'].mean():.1f}")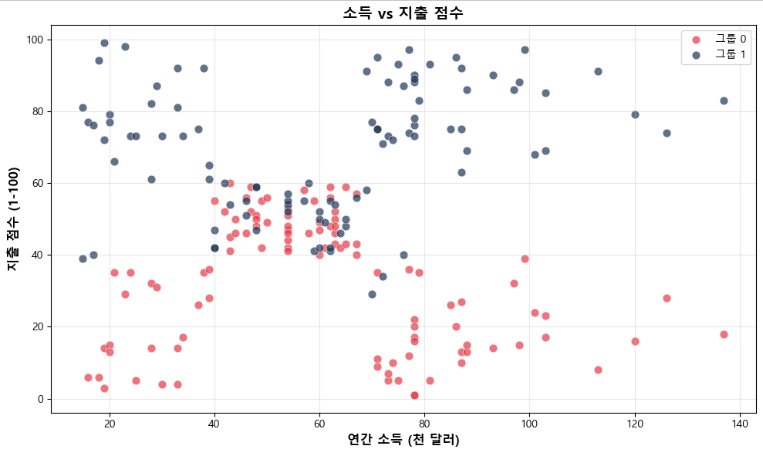

그룹별 통계:
그룹 0 (n=103)
평균 나이: 48.7세
평균 소득: $60.5k
평균 지출점수: 32.2
그룹 1 (n=97)
평균 나이: 28.4세
평균 소득: $60.6k
평균 지출점수: 69.3
'삼정KPMG Future Academy > 머신러닝&딥러닝' 카테고리의 다른 글
| CNN (0) | 2025.12.05 |
|---|---|
| 다중분류 문제 해결, CNN (-ing) (0) | 2025.12.04 |
| 딥러닝 기초 (Numpy, Tensorflow) (0) | 2025.12.03 |
| Logistic Regression, Confusion Matrix, Decision Tree (0) | 2025.11.27 |
| 데이터분석과 머신러닝 기본 (0) | 2025.11.25 |

