로지스틱 회귀(Logistic Regression)
- 입력값 X로부터 어떤 사건이 발생할 확률(0~1)을 예측하는 모델
- 선형 회귀 결과를 확률로 변환하여 이진분류 문제를 해결하는 방법
- 이진분류와 다중 클래스 분류에 사용됨
- 이름에 회귀(regression)가 들어가지만 실제로는 확률을 예측하고 이를 기준으로 클래스를 나누므로 분류(classification)에 속함
Logistic Regression 사용 이유
- 일반 선형식(ex> $z=w_1x_1+w_2x_2+b$)을 사용하면 결정경계를 만들 수 있음
- but 단순한 선형 조합의 결과는 $-infin$에서 $+infin$까지 나오므로 이 값을 확률(0~1)로 바꿔주는 함수가 필요
- 시그모이드(sigmoid) 함수가 그 역할을 함
시그모이드(sigmoid) 함수
: S자 모양으로 모든 실수를 0~1사이로 매핑해줌
: $\sigma(z)=\frac{1}{1+e^{-z}}$
- odds: 어떤 사건이 발생할 확률 p에 대해, 이 사건이 발생할 확률과 발생하지 않을 확률의 비율
$odds(p)=\frac{1}{1-p}$ - Log-odds: 확률을 선형 회귀 모델로 표현
확률 p의 범위(0, 1) 선형회귀의 반환값 ( $-infin$, $+infin$)에 대응하기 위함
$\log{(odds(p))}=w_1x+w_0=z$ - 데이터 x에 대한 예측 확률 p로 정리
$P(Y=1|x)=\frac{1}{(1+e)^{-()w_1x+w_0}}$ - 예측 확률이 0.5 이상이면 1
0.5 미만이면 0으로 예측
정규화
- L2: Ridge
- L1: Lasso
- C: 규제 강도를 조절하는 alpha 값의 역수
값이 작을수록 규제 강도가 큼
실습
lib와 데이터 로딩
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd문제 정의
- 나이와 연봉으로 분석해서, 물건을 구매할지 안할지를 분류하기
- 어떤 고객이 구매할 가능성이 높은지 예측
- 고객 세분화 : 나이, 성별, 연봉에 따른 구매 패턴 분석
- 마케팅 타겟팅 : 구매 가능성 높은 고객군 식별
데이터 수집
마케팅 / 광고 캠페인 반응 데이터
- User ID: 고객 ID
- Gender: 성별 (Male/Female)
- Age: 나이
- EstimatedSalary: 추정 연봉
- Purchased: 구매 여부 (0=구매 안 함, 1=구매함)
data_path = 'path 정의'
df = pd.read_csv(data_path)
df.head()label 또는 Y의 컬럼의 value_counts() 출력
df['Purchased'].value_counts()데이터 EDA 수행
df.info()데이터 전처리
df.head()
df.columnsX, y 데이터로 분할
# X = df.loc[ 행, 열]
# X = df.loc[: , ['Gender', 'Age', 'EstimatedSalary']]
# 범위로 하는법
X = df.loc[:, 'Gender':'EstimatedSalary']
X.head()
# y
y = df['Purchased']
y
X['Gender'].value_counts()
# map()함수 사용
mapping = {'Male': 0, 'Female': 1}
X['Gender'] = X['Gender'].map(mapping)
X.head()Feature Scaling
from sklearn.preprocessing import StandardScaler, MinMaxScaler
# 객체생성
X_scaler = StandardScaler()
X_scaler
# X_scaler.fit(X)
# X_scaler.transform(X)
# 위의 두 문장을 한번에 처리하는 문장
X_scaled = X_scaler.fit_transform(X)학습, 테스트 데이터 분할
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
X_scaled, y,
test_size=0.25,
random_state=2025,
stratify = y
)
X_test.shape, y_test.shape모델 학습 및 평가
모델 객체생성
from sklearn.linear_model import LogisticRegression
# 모델객체 생성(빈 깡통)
model_logrc = LogisticRegression()
model_logrc학습하기
model_logrc.fit(X_train, y_train)
# 확률값을 넣어야하니까
y_pro = model_logrc.predict_proba(X_test)
y_pred = model_logrc.predict(X_test)
# y_pro, Y_pred 로 비교하기
y_result = pd.DataFrame(y_pro)
y_result['y_pred'] = y_pred
# y_pro, y_pred 로 비교하기
y_df = pd.DataFrame({'y_pro_0': y_pro[:, 0], 'y_pro_1': y_pro[:, 1], 'y_pred': y_pred, 'y_test': y_test})
y_df.head(10)모델 테스트
# 모의고사 보는 것
y_pred = model_logrc.predict(X_test)
# w1, w2, w3
model_logrc.coef_
# w0 (bias)
model_logrc.intercept_
# 확률값을 넣어야함
model_logrc.predict_proba(X_test)모델 평가하기
- 지도학습은 기본적으로 정확도를 확인함
정확도 (accuracy)
# 정확도
(y_test == y_pred).sum() /len(y_test) *100
# 실제 1인데, 예측 1로 한것
# 실제 0인데, 예측 1으로 한것
# 실제 1인데, 예측 0으로 한것
# 실제 0인데, 예측 0으로 한것
# 이것을 컨퓨전 매트릭스(혼동행렬)Confusion Matrix
- 예측값(Predicted)과 실제값(Actual)을 비교한 2x2 테이블
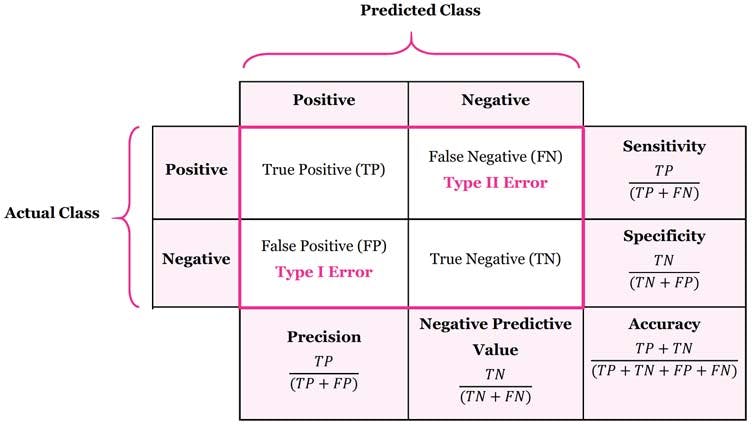
- TP (True Positive) : 실제 - Positive, 예측 - Positive (T)
- FP (False Positive) : 실제 - Negative, 예측 - Positive (F)
- FN (False Negative) : 실제 - Positive, 예측 - Negative (F)
- TN (True Negative) : 실제 - Negative, 예측 - Negative (T)
계산 가능한 평가 지표
- Accuracy (정확도)
$\frac{TP+TN}{TP+FP+FN+TN}$ - Precision (정밀도)
$\frac{TP}{TP+FP}$ - Recall (재현율)
$\frac{TP}{TP+FN}$ - F1-score: Precision과 Recall의 조화평균
$2*\frac{Precision*Recall}{Precision+Recall}$
from sklearn.metrics import confusion_matrix
# confusion_matrix(실제값, 예측값)
cm = confusion_matrix(y_test, y_pred)
정밀도(precision), 재현율(적중율, recall)
from sklearn.metrics import recall_score, precision_score
from sklearn.metrics import classification_report
# 재현률
recall_score(y_test, y_pred)
# 정밀도
precision_score(y_test, y_pred)
# ML의 분류제 종합 평가 함수
print(classification_report(y_test, y_pred))모델 결과를 보고 전략 수립
import seaborn as sb
sb.heatmap(data=cm, annot=True)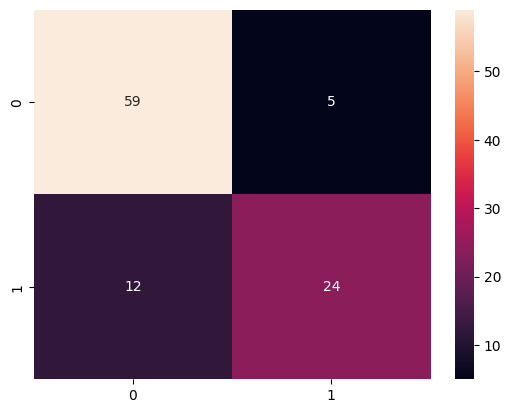
분류 결과 시각화
from sklearn.decomposition import PCA
from matplotlib.colors import ListedColormap
# 3D → 2D 차원 축소
pca = PCA(n_components=2)
X_test_2d = pca.fit_transform(X_test)
# 2D meshgrid
X1, X2 = np.meshgrid(
np.arange(X_test_2d[:, 0].min() - 1, X_test_2d[:, 0].max() + 1, 0.01),
np.arange(X_test_2d[:, 1].min() - 1, X_test_2d[:, 1].max() + 1, 0.01)
)
# 원래 3D 공간으로 역변환 후 예측
X_grid_2d = np.c_[X1.ravel(), X2.ravel()]
X_grid_3d = pca.inverse_transform(X_grid_2d)
predictions = model_logrc.predict(X_grid_3d).reshape(X1.shape)
# 시각화
plt.figure(figsize=(10, 7))
plt.contourf(X1, X2, predictions,
alpha=0.75, cmap=ListedColormap(('red', 'green')))
for i, j in enumerate([0, 1]):
plt.scatter(X_test_2d[y_test == j, 0],
X_test_2d[y_test == j, 1],
c='darkred' if j == 0 else 'darkgreen',
label=f'Purchased={j}',
edgecolors='white',
s=100,
linewidth=1.5)
plt.xlabel(f'PC1 ({pca.explained_variance_ratio_[0]:.1%})', fontsize=12)
plt.ylabel(f'PC2 ({pca.explained_variance_ratio_[1]:.1%})', fontsize=12)
plt.title('Decision Boundary (PCA)', fontsize=14, fontweight='bold')
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()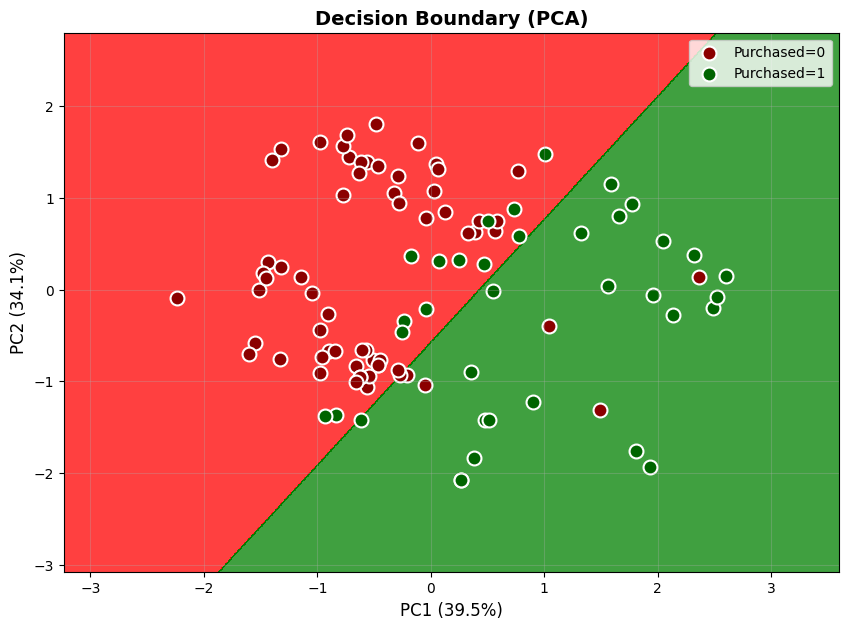
Decision Tree
- 데이터에 있는 규칙을 학습을 통해 자동으로 찾아내 트리 기반으로 분류 규칙을 만듦(if, else 기반 규칙)
- 데이터의 어떤 기준을 바탕으로 규칙을 만들어야 가장 효율적인 분류가 될 것인지가 알고리즘의 성능을 크기 좌우함
- 데이터 마이닝에서 일반적으로 사용되는 방법론
- 몇몇 입력변수를 바탕으로 목표 변수의 값을 예측하는 모델 생성을 목표로 함
- 가지, 자식(child) 노드, 잎(leaf) 노드로 구성

실습
lib와 데이터 로딩
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import warnings
warnings.filterwarnings('ignore')
data_path = 'data path 지정'
df = pd.read_csv(data_path)
df.head()
df.info()
y = df['Purchased']
X = df.loc[:, 'Gender' : 'EstimatedSalary']
# 방법1: map 사용(가장 직관적)
X['Gender'] = X['Gender'].map({'Male':0, 'Female':1})
# 방법2:
# X['Gender'] = X['Gender'].replace({'Male':0, 'Female':1})
y.value_counts()train, test 데이터 분할
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=7)
X_train.shape, y_train.shape
X_test.shape, y_test.shape모델학습
from sklearn.tree import DecisionTreeClassifier
classifier = DecisionTreeClassifier()
classifier.fit(X_train, y_train)
y_pred = classifier.predict(X_test)
from sklearn.metrics import classification_report, accuracy_score
# y_test: 실제 라벨, y_pred: 모델 예측 라벨
print('정확도:', accuracy_score(y_test, y_pred))
print('\n[정밀도, 재현율, F1-score 요약 보고서]')
print(classification_report(y_test, y_pred))'삼정KPMG Future Academy > 머신러닝&딥러닝' 카테고리의 다른 글
| CNN (0) | 2025.12.05 |
|---|---|
| 다중분류 문제 해결, CNN (-ing) (0) | 2025.12.04 |
| 딥러닝 기초 (Numpy, Tensorflow) (0) | 2025.12.03 |
| 비지도학습 K-Means (0) | 2025.12.02 |
| 데이터분석과 머신러닝 기본 (0) | 2025.11.25 |

