머신러닝 개요
머신러닝
머신러닝
- 명시적인 프로그램 없이 기계가 데이터를 이용해서 학습하고 예측 수행하는 알고리즘을 구현하는 기법
- 과거 경험에서 학습을 통해 얻은 지식을 미래의 결정에 이용하는 컴퓨터 과학의 한 분야
- 관측된 패턴을 일반화하거나 주어진 샘플을 통해 새로운 규칙을 생성하는 목표를 가짐
머신러닝 방법론
- 문제 정의 (Problem Definition)
- 데이터 수집 (Data Collection)
- 데이터 EDA (Exploratory Data Analysis)
- 데이터 전처리 (Preprocessing)
- 모델 선택 (Model Selection)
- 모델 학습 (Training)
- 모델 평가 (Evaluation)
- 모델 배포 (Deployment)
- 모니터링 & 개선 (Monitoring)
예측모델
예측모델 필요성
- 중요한 비즈니스적 의사결정을 안정적이고 계획적으로 수행 가능
## 머신러닝 학습 방법
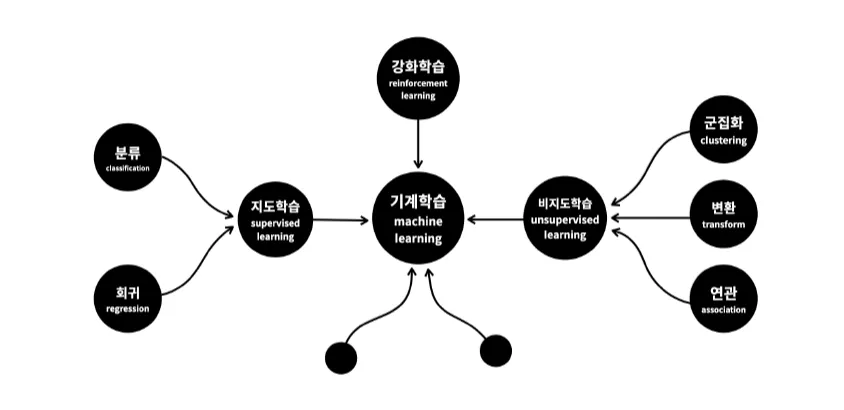
지도학습 (Supervised Learning)
- 학습 데이터가 입력과 출력 쌍으로 제공
- 입력: 특징, 행렬, Feature, 독립변수
- 출력: 대상 벡터, 정답, 레이블, Target
- 머신러닝 학습 모델의 목표: 입력 특징 행렬과 출력 대상 벡터를 맵핑시키는 규칙을 찾는 것
- 입력 데이터와 출력 정답을 알려줘서 학습하므로 지도라고 함
- 딥러닝의 95% 이상이 지도학습을 사용 (CNN, RNN)
분류(Classification)문제 vs 회귀(Regression)문제
- 분류문제: 예측하는 결과값이 이산값인 경우
- 회귀문제: 예측하는 결과값이 연속된 숫자 값인 경우
비지도학습
- 학습데이터 x만을 이용해서 학습하는 방법
- 데이터의 숨겨진 특징을 찾아내는 것이 목적
- 데이터가 무작위로 분포되어있을 때, 공통된 특징을 가진 그룹으로 묶기
- 비지도학습은 단독으로 사용하기보다는 비지도학습으로 파악한 데이터의 숨겨진 특징을 원본 데이터 대신 지도학습의 성능을 더욱 끌어올리는 용도로 활용됨
강화학습
- 피드백을 바탕으로 성능을 평가하고, 그에 따라 반응하는 학습법
- 시스템이 어떤 목표를 달성하기 위해 동적인 조건에 대응하도록 함
- 학습하는 에이전트가 주어진 환경에서 어떤 행동을 취하고 이에 대한 보상을 얻으면서 학습 진행
- 시간이 경과하면서 가장 큰 보상을 얻기 위해 최상의 전략을 스스로 학습
머신러닝 회귀모델 실습
환경설정
- github repository 만든 후 git clone (폴더명: ml_ex)
- pip show scikit-learn → 없으면 pip install -U scikit-learn 해서 stable ver. 설치
데이터 로딩 및 단위 변경
# read weight-height dataset
data = "datas_ml/weight-height.csv"
wh_df = pd.read_csv(data)
wh_df.head()[문제해결] 컬럼 단위를 우리에게 익숙한 값으로 변경하기
- 키: inch -> cm, 1inch = 2.54cm
- 몸무게: lb (파운드) -> kg, 1lb - 0.4563kg
방법
# read weight-height dataset
data = "datas_ml/weight-height.csv"
wh_df = pd.read_csv(data)
# 키 변경하기
wh_df["Height"] =
# 몸무게 변경하기
wh_df["Weight"] =
wh_df.head()
wh_df.shape데이터 탐색
wh_df.info()
#[문제] 기초 통계량 확인
wh_df.describe()
wh_df['Gender'].describe()
# 키와 몸무게 분포 확인
sns.scatterplot(data=wh_df, x = 'Height', y = 'Weight')
plt.show()키에 따른 몸무게 예측
학습, 테스트 데이터 준비
- Feature(x)와 label(y) 데이터 분리
x = wh_df["Height"] # 입력데이터
y = wh_df["Weight"] # 정답데이터
y[:5]80%는 트레이닝 데이터, 20%는 테스트 데이터로 나누기
- random_seed 값 주기
- stratify=y 설정은
- target이 classification인 경우
- feature가 2개이상 있을 때 사용
# 학습, 테스트 데이터셋으로 분할
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=10)회귀모델 학습하기
- 선형회귀 (Linear Regression)
model_lr = LinearRegression()
x_train.shape
# x_train 데이터가 1D 이면 오류 발생함
model_lr.fit(x_train, y_train)
x_train.shape
# x는 2차원이어야 함.
x_train_2d = x_train.values.reshape(-1,1)
# 모델 학습
# model_lr.fit(x_train, y_train) <-- x_train은 2D 여야함.
model_lr.fit(x_train_2d, y_train)[TIP] feature가 1개인 경우, 학습 및 테스트 시 reshape(-1,1)로 차원을 바꿔 주는 이유
- 학습기는 기본적으로 feature 2개 이상의 input이 들어간다고 가정하고 만들어뒀다.(2차원 array)
- 현재 키(height)만 있음.(1차원 vector)
학습 모델 테스트
#print(type(x_test))
print("테스트 데이터", x_test.values)
print()
print(x_train_2d)
# 테스트 데이터에 대한 예측을 수행
y_pred = model_lr.predict(x_test.values.reshape(-1,1))
y_pred
model_lr.coef_
model_lr.intercept_모델 성능 평가하기
- MSE(Mean Squared Error)를 측정하기
- RMSE(Root Mean Squared Error)를 측정하기
y_test[:5]
# MSE(Mean Squared Error)
MSE = mean_squared_error(y_test, y_pred)
# RMSE(Root Mean Squared Error)를 측정하기
RMSE = np.sqrt(MSE)
print('MSE :', MSE)
print('RMSE :', RMSE)
# 결과는 도메인마다 다름ML 모델 일반화
방법1 :
lr.predict([[165]])
방법2:
y_pred2 = lr.predict(np.array([177,185]).reshape(-1,1))
y_pred2
방법3:
my_height1 = pd.Series(172)
type(my_height1)
model_lr.predict(my_height1.values.reshape(-1,1))예측 결과 시각화
plt.plot(x_test, y_test, 'o')
plt.plot(x_test, y_pred)
plt.title('Weight and Height Prediction')
plt.show()
키와 성별에 따른 몸무게 예측하기
- feature 갯수 2개로 학습하기
- Gender, height 데이터로 linear regression 모델 만들기
- Gender는 범주형 데이터임 : One Hot Encoding으로 변환하기
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error데이터 로딩 및 가공
# read weight-height dataset
data = "datas_ml/weight-height.csv"
gwh_df = pd.read_csv(data)
gwh_df.head()
# 인치, 파운드 -> cm, kg으로 변환
gwh_df["Height"] = gwh_df["Height"] * 2.54
gwh_df["Weight"] = gwh_df["Weight"] * 0.4563
# read weight-height dataset
gwh_df.head()
# feature distribution
sns.histplot(data=gwh_df, x="Height", hue="Gender")
plt.figure(figsize=(10,6))ML을 위한 Feature Engineering
- 범주형 데이터 숫자로 변환: One Hot Encoding
gwh_df['Gender'].value_counts()
# Gender 컬럼을 숫자로 변환
gwh_df['Gender'] = gwh_df['Gender'].map({"Male": 0, "Female": 1})
gwh_df.head()학습, 테스트 데이터 준비
# X = Gender, Height
X = gwh_df.drop(columns='Weight')
# y = Weight
y = gwh_df['Weight']
X.head()
# train data : test data로 분할 (8 : 2)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=10)
X_train회귀 모델 학습
# 학습모델 객체생성, 학습, 테스트
model_lr2 = LinearRegression()
model_lr2.fit(X_train, y_train)테스트 및 성능 평가
y_pred = model_lr2.predict(X_test)
y_pred
X_test.columnsML 모델 일반화
my_test = [[1, 165]]
my_test
model_lr2.predict(my_test)
X_test[:5]
plt.plot(X_test.loc[:,'Height'], y_test, 'o') # 실제값 표시
plt.plot(X_test.loc[:,'Height'], y_pred, '^') # 예측값 표시
plt.title('Weight and Height Prediction')
plt.xlabel('height')
plt.ylabel('weight')
plt.show()
데이터 전처리
머신러닝으로 할 수 있는 것
- 편지봉투에 손으로 쓴 우편번호 숫자 자동 판별
- 의료 영상 이미지에 기반한, 종양 판단
- 의심되는 신용카드 거래 감지
- 블로그 글의 주제 분류
- 고객들을 취향이 비슷한 그룹으로 묶기
문제와 데이터 이해하기
- 가지고 이는 데이터가 내가 원하는 문제의 답을 가지고 있는가?
- 내 문제를 가장 잘 해결할 수 있는 머신러닝 방법은 무엇인가
- 문제를 풀기에 충분한 데이터를 모았는가?
- 머신러닝의 성과를 어떻게 측정할 것인가
머신러닝: Supervised
Regression(회귀)과 Classification(분류)
Regression
- 예 ) 어떤 사람의 교육수준, 나이, 주거지를 바탕으로 연간 소득을 예측하는 것
- 예 ) 옥수수 농장에서 전년도 수확량과 날씨, 고용 인원수 등으로 올해 수확량을 예측하는 것
Classification
- 예) 웹사이트가 어떤 언어로 되어있는가
- 예) 사진을 보고, 고양이 인지 강아지 인지, 소인지 분류
Training과 Test
훈련이란, 데이터를 입력하고, 그 결과인 레이블이 나오도록 만드는 과정.
즉, 데이터와 레이블을 통해 학습을 시키는 과정
테스트란, 학습이 완료된 분류기에 학습에 사용하지 않은 데이터를 넣어서 정답을 맞추는지 확인하는 작업
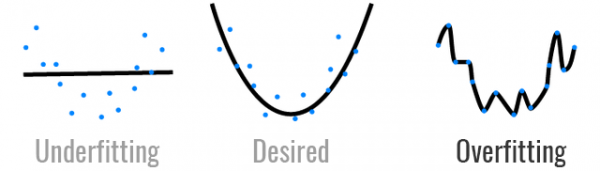
Generalization
모델이 처음 보는 데이터에 대해 정확하게 예측할 수 있는 능력
Overfitting
모델이 훈련 데이터에만 지나치게 맞춰져서, 새로운 데이터를 예측할 때 성능이 떨어지는 상태.
Underfitting
모델이 훈련 데이터조차 제대로 학습하지 못한 상태.
환경설정
#sklearn 설치
# pip install scikit-learn
# Importing the libraries
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd데이터셋 로딩 및 df 만들기
df = pd.read_csv("./datas_ml/Data.csv")
# 온라인 소핑목 고객 데이터라고 가정, 이 소핑목에서 물건을 구매했으면, Purchased 가 yes
df.head()
sorted(df['Country'].unique())
# sorted(df['Purchased'].unique())
sorted(df['Purchased'].unique())결측치(NaN) 처리
# 결측치 확인
df.info()
df.isna().sum()- 결측치 처리 방법
# 삭제하기
# NaN이 포함된 행을 삭제 (df에 반영)
df.dropna()
# 채우기
df.fillna(0)
df.fillna(df['Age'].mean())
df.mean(numeric_only=True)
# 숫자 컬럼의 평균값으로 결측치 채우기
df.fillna(df.mean(numeric_only=True), inplace=True)
df
# index 초기화(reset) 하기
df.reset_index(drop=True, inplace=True)
dfX, y 데이터 분리(분할)
- X: 독립변수(Feature)
- y: 종속변수(Target, Label)
# 우리가 예축하고자 하는 것 y
y = df['Purchased']
y
# X 컬럼: Country, Age, Salary
# X = df.loc[행, 열]
X = df.loc[:, 'Country' : 'Salary']
X
df['Country'].value_counts()레이블 인코딩, One Hot Encoding
- 범주형(문자) 데이터를 숫자로 변환
- 레이블 인코딩: 문자열 -> 0, 1, 2,...
- One Hot Encoding:
'삼정KPMG Future Academy > 머신러닝&딥러닝' 카테고리의 다른 글
| CNN (0) | 2025.12.05 |
|---|---|
| 다중분류 문제 해결, CNN (-ing) (0) | 2025.12.04 |
| 딥러닝 기초 (Numpy, Tensorflow) (0) | 2025.12.03 |
| 비지도학습 K-Means (0) | 2025.12.02 |
| Logistic Regression, Confusion Matrix, Decision Tree (0) | 2025.11.27 |

